Building a data pipeline can be a complex task, especially when integrating multiple services and platforms. In this article, we’ll walk through the process of creating a data pipeline that fetches data from Reddit, uses Apache Airflow for orchestration, stores the data in Amazon S3, processes it with AWS Glue, queries with Amazon Athena, and finally, loads it into Amazon Redshift for analysis.
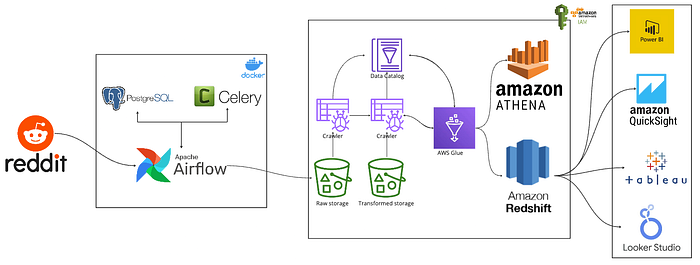
1. Overview of the Architecture
- Reddit: A vast source of user-generated content.
- Airflow: Orchestrates the workflow of fetching, processing, and loading data.
- S3: Provides scalable storage.
- AWS Glue: ETL service that prepares and loads data for analysis.
- Athena: Interactive query service.
- Redshift: Data warehousing service for analysis.
If you’re interested in following the step by step video, you can watch below: