Google’s Bidirectional Encoder Representations from Transformers (BERT) is a large-scale pre-trained autoencoding language model developed in 2018. Its development has been described as the NLP community’s “ImageNet moment”, largely because of how adept BERT is at performing downstream NLP language understanding tasks with very little backpropagation and fine-tuning needed (usually only 2–4 epochs).
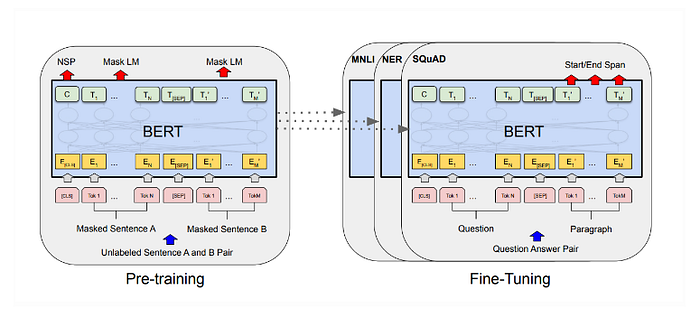
Source: Devlin et al. (2019)
For context, traditional word embeddings (e.g. word2vec and GloVe) are non-contextual. They represent each word token with a single static vector, and learn by word co-occurence instead of the sequential context of words. This may be problematic when words are polysemous (i.e. where the same word has multiple different meanings), which is very common in law.