Due to its extensive functionality and versatility, pandas has secured a place in every data scientist’s heart.
From data input/output to data cleaning and transformation, it’s nearly impossible to think about data manipulation without import pandas as pd, right?
Now, bear with me: with such a buzz around LLMs over the past months, I have somehow let slide the fact that pandas has just undergone a major release! Yep, pandas 2.0 is out and came with guns blazing!
Although I wasn’t aware of all the hype, the Data-Centric AI Community promptly came to the rescue:
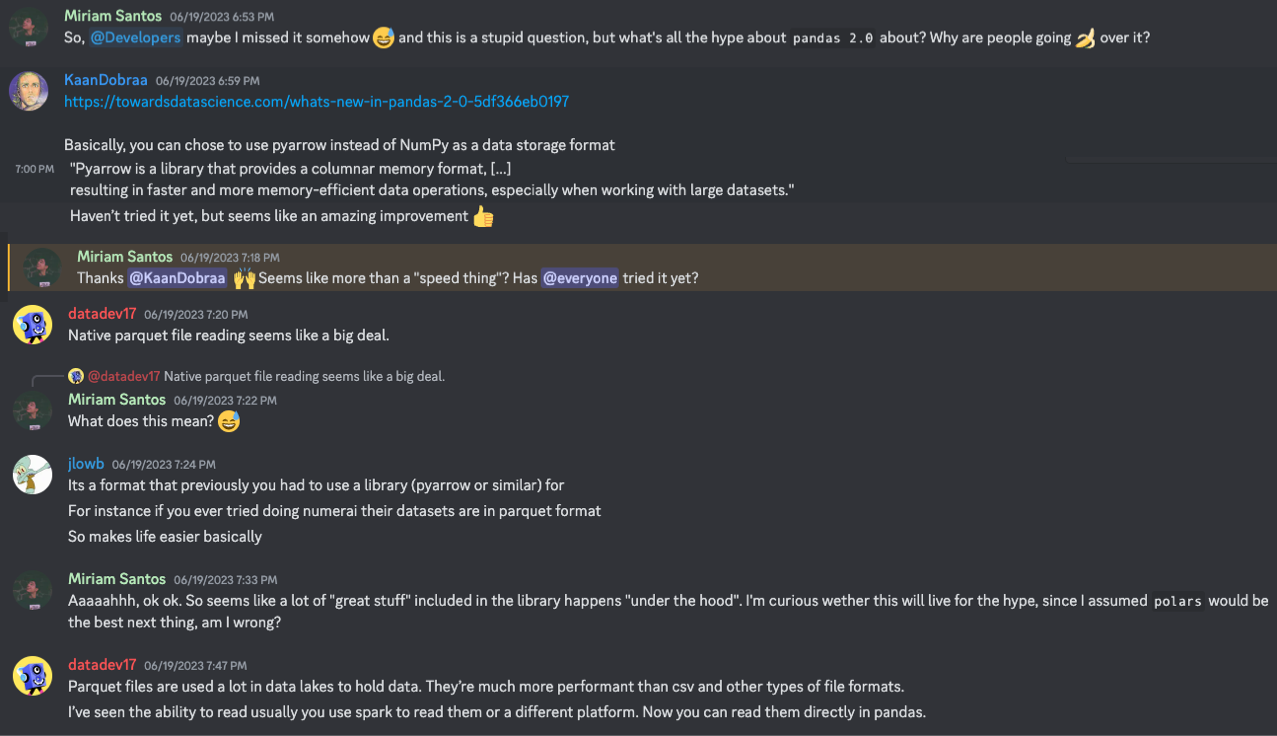
The 2.0 release seems to have created quite an impact in the data science community, with a lot of users praising the modifications added in the new version. Screenshot by Author.
Fun fact: Were you aware this release was in the making for an astonishing 3 years? Now that’s what I call “commitment to the community”!
So what does pandas 2.0 bring to the table? Let’s dive right into it!
1. Performance, Speed, and Memory-Efficiency
As we all know, pandas was built using numpy, which was not intentionally designed as a backend for dataframe libraries. For that reason, one of the major limitations of pandas was handling in-memory processing for larger datasets.
In this release, the big change comes from the introduction of the Apache Arrow backend for pandas data.
Essentially, Arrow is a standardized in-memory columnar data format with available libraries for several programming languages (C, C++, R, Python, among others). For Python there is PyArrow, which is based on the C++ implementation of Arrow, and therefore, fast!