Expert models are one of the most useful inventions in Machine Learning, yet they hardly receive as much attention as they deserve. In fact, expert modeling does not only allow us to train neural networks that are “outrageously large” (more on that later), they also allow us to build models that learn more like the human brain, that is, different regions specialize in different types of input.
In this article, we’ll take a tour of the key innovations in expert modeling which ultimately lead to recent breakthroughs such as the Switch Transformer and the Expert Choice Routing algorithm. But let’s go back first to the paper that started it all: “Mixtures of Experts”.
Mixtures of Experts (1991)
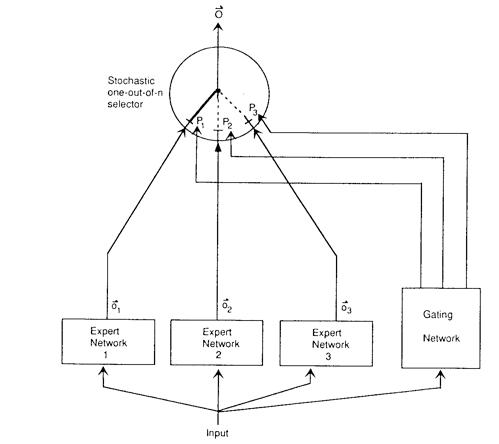
The original MoE model from 1991. Image credit: Jabocs et al 1991, Adaptive Mixtures of Local Experts.
The idea of mixtures of experts (MoE) traces back more than 3 decades ago, to a 1991 paper co-authored by none other than the godfather of AI, Geoffrey Hinton. The key idea in MoE is to model an output “y” by combining a number of “experts” E, the weight of each is being controlled by a “gating network” G:
An expert in this context can be any kind of model, but is usually chosen to be a multi-layered neural network, and the gating network is