Search is the base of many applications. Once data starts to pile up, users want to be able to find it. It’s the foundation of the internet and an ever-growing challenge that is never solved or done.
The field of Natural Language Processing (NLP) is rapidly evolving with a number of new developments. Large-scale general language models are an exciting new capability allowing us to add amazing functionality. Innovation continues with new models and advancements coming in at what seems a weekly basis.
This article introduces txtai, an all-in-one embeddings database that enables Natural Language Understanding (NLU) based search in any application.
Introducing txtai
txtai is an all-in-one embeddings database for semantic search, LLM orchestration and language model workflows.
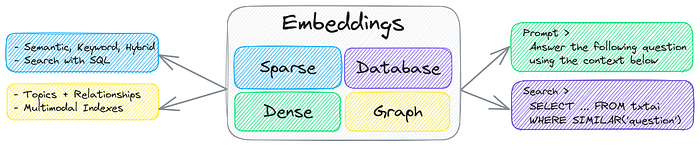
Embeddings databases are a union of vector indexes (sparse and dense), graph networks and relational databases. This enables vector search with SQL, topic modeling, retrieval augmented generation and more.