Before getting started let’s discuss the problem statement in hand. I wanted to analyze some data stored in a text file. Each row contained four numerical values demlimited by a space, for a total of 46.66M rows. The size of the file is around 1.11 GB, and I am attaching a small screen shot of the data below so that you get the idea what it looks like.
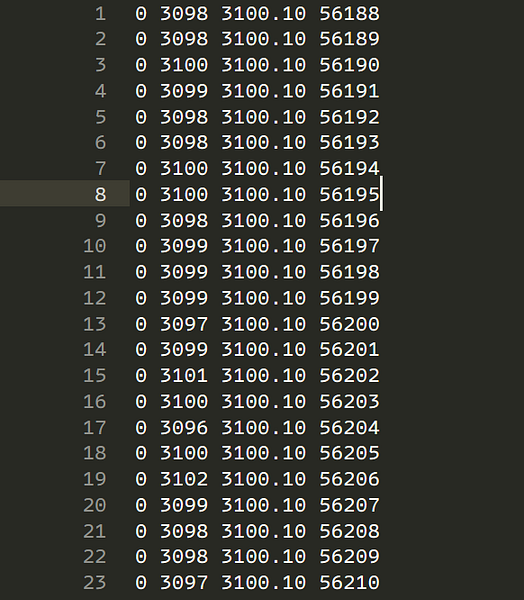
I needed to extract only the rows for a given value of the third column (3100.10 in the image above) The first thing I tried was to simply use numpy.genfromtxt() but it gave memory error as the data is too big to handle at once.
I tried to segment the data into smaller chunks and do the same, but it was painfully slow so I tried various things to get the job done in the fastest possible way. I will show you the code along with the concepts I used to optimise my code.
def Function1():
output="result.txt"
output_file=open(output, "w")
value=3100.10
with open(file, "r") as f:
for line in f:
if(line!="\n"):
if(len(line.split(" "))==4):
try:
if(int(float(line.split(" ")[2]))==int(value)):
output_file.write(line)
except ValueError:
continue
f.close()
output_file.close()
Starting Point
This is the most basic approach to solving this problem. Iterate through the entire file line by line, check if the line(row) contains that value, if it does then append the row to a new file.