Large language models such as ChatGPT process and generate text sequences by first splitting the text into smaller units called tokens. In the image below, each colored block represents a unique token. Short or common words such as “you”, “say”, “loud”, and “always” are its own token, whereas longer or less common words such as “atrocious”, “precocious”, and “supercalifragilisticexpialidocious” are broken into smaller subwords.
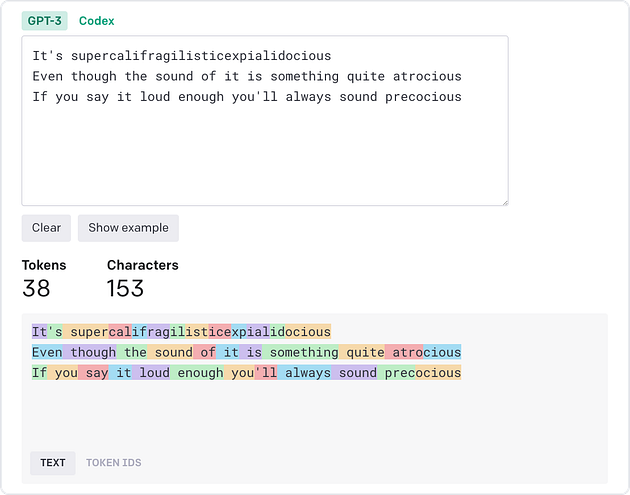
Visualization of tokenization of a short text using OpenAI’s tokenizer website. Screenshot taken by author.
This process of tokenization is not uniform across languages, leading to disparities in the number of tokens produced for equivalent expressions in different languages. For example, a sentence in Burmese or Amharic may require 10x more tokens than a similar message in English.

An example of the same message translated into five languages and the corresponding number of tokens required to tokenize that message (using OpenAI’s tokenizer). The text comes from Amazon’s MASSIVE dataset.
In this article, I explore the tokenization process and how it varies across different languages:
- Analysis of token distributions in a parallel dataset of short messages that have been translated into 52 different languages
- Some languages, such as Armenian or Burmese, require 9 to 10 times more tokens than English to tokenize comparable messages
- The impact of this language disparity